My NAS is currently running Ubuntu 22.04.5 LTS. I have tried in the past to perform a do-release-upgrade, and ended up with a system that will not boot.
Since then, I have moved many services away from the NAS. I thought I should give it one more try, and I did just that yesterday. Unfortunately the result ended up the same, resulting another rescue.
I thought I should document the rescue process here again.
# Wipe the root fs
mkfs.ext4 /dev/nvme1n1p2
# Restore from backup
mount /dev/nvme1n1p2 /mnt
mount /dev/backup_partition /mntb
rsync -aAXv /mntb/ /mnt/
# Ensure the root file system new UUID is the same in /etc/fstab
vi /mnt/etc/fstab
# chroot to install the boot partition
mount /dev/nvme1n1p1 /mnt/boot/efi
for i in /dev /dev/pts /proc /sys /run; do mount -B $i /mnt$i; done
mount -t efivarfs efivarfs /mnt/sys/firmware/efi/efivars
chroot /mnt
# Identify your EFI partition again just in case (e.g., /boot/efi)
sudo grub-install
# Below is more forceful but mostly optional and unnecessary
# grub-install --target=x86_64-efi --efi-directory=/boot/efi --bootloader-id=GRUB --removable --recheck
sudo update-grub
exit
# Exit and reboot
umount -l /mnt
reboot
By now I have become an expert in rescuing failed upgrades with Ubuntu.
I have upgraded my TUF GAMING B550-PLUS motherboard to version 3636. This is a recently released BIOS from ASUS in January of 2026. My previous version of the BIOS was from 2024.
I will give myself another breather, say about a week, before attempting to try again.
In a previous post, one of our two SolarEdge inverters encountered an error and one quick fix is to reset the inverters. This year we had a similar issue.
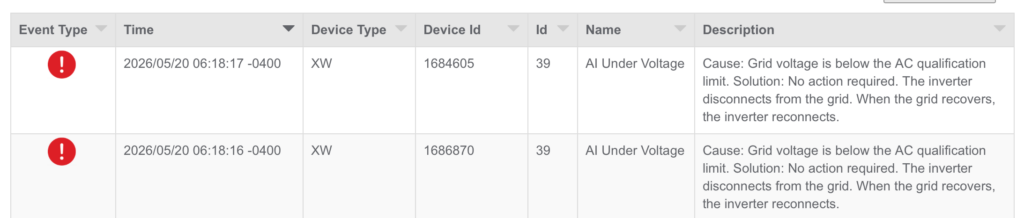
Three days ago, our solar system encountered a grid voltage issue. Our XWPro inverter was in AC PassThru mode causing the SolarEdge inverters to detect the same grid issue. Our solar system is AC coupled. With XWPro handling grid-tied net metering, and battery charging and discharging, and SolarEdge for solar energy generation.
AC Qualification Limit Exceeded
This grid event cause both SolarEdge inverters to go into a “Grid Profile Limit” mode where its AC output was limited to around 100W. When I reset both inverters through the main breaker panel, one recovered while the other continue with the limited output behaviour. To fix the second one, I had to perform a hard reset on the inverter. Below are the steps needed.
Main Breaker Panel
SolarEdge Inverter Control Positions
First I had to switch off the inverter at position A, and then turn off the DC disconnect at position B. I then had to switch off the breaker on the main panel.
The important part is to wait 5 to 10 minutes to wait for the inverter to discharge for the full reset to happen.
Once the time has passed, perform the action in reverse. Turn back on the breaker, the DC disconnect (B), and then finally turn back on the inverter (A).
Luckily after this hard reset procedure, the second SolarEdge inverter has been fully restored with normal operation.
Over the past few years I have developed several services that can be accessed using a web site. Many if not all of these sites require authentication. In the past I have typically adopted a typical user id and password technique, and more recently an email based authentication along with the user’s external IP address, so that they do not need to be burdened with remembering the password.
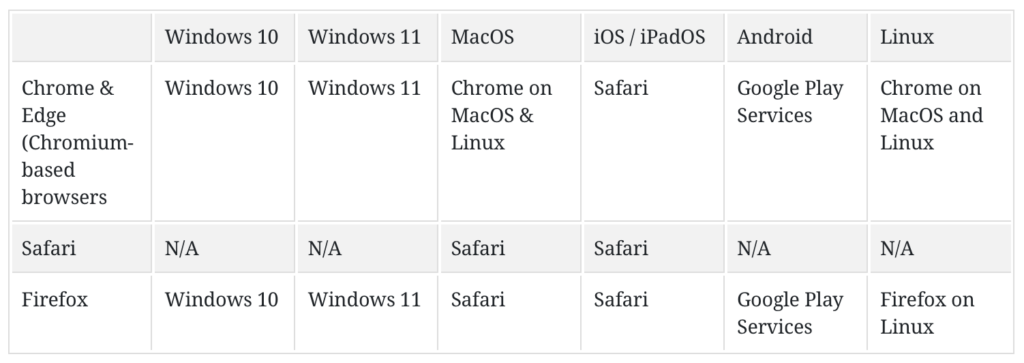
When my iPhone started to adopt the WebAuthn passkey solutions I wanted to make use of this convenient solution for my sites as well. As you can see from the chart below, the adoption across the different platforms and devices are now universal.
Compatibility List
I went about to develop my own identity provider server using the python WebAuthn package. Why did I develop my own solution and instead of using one of the open source solution? I wanted to learn how this works, and what better way to do it than implementing my own version. I also wanted to customize it based on a list of authorized email with the ability to track and manage the access.
This was also the first solution where I used AI to help me vibe code the browser side of the solution. It used the navigator.credentials object to do most of the heavy lifting. The AI generated code at the time is fraught with many errors and bad assumptions which I had fix manually. This was more than a year ago, so I am sure things have improved by now.
In the end, I deployed this custom identity service on auth.lufamily.ca. This custom service also handled the email authentication flow, which goes something like this:
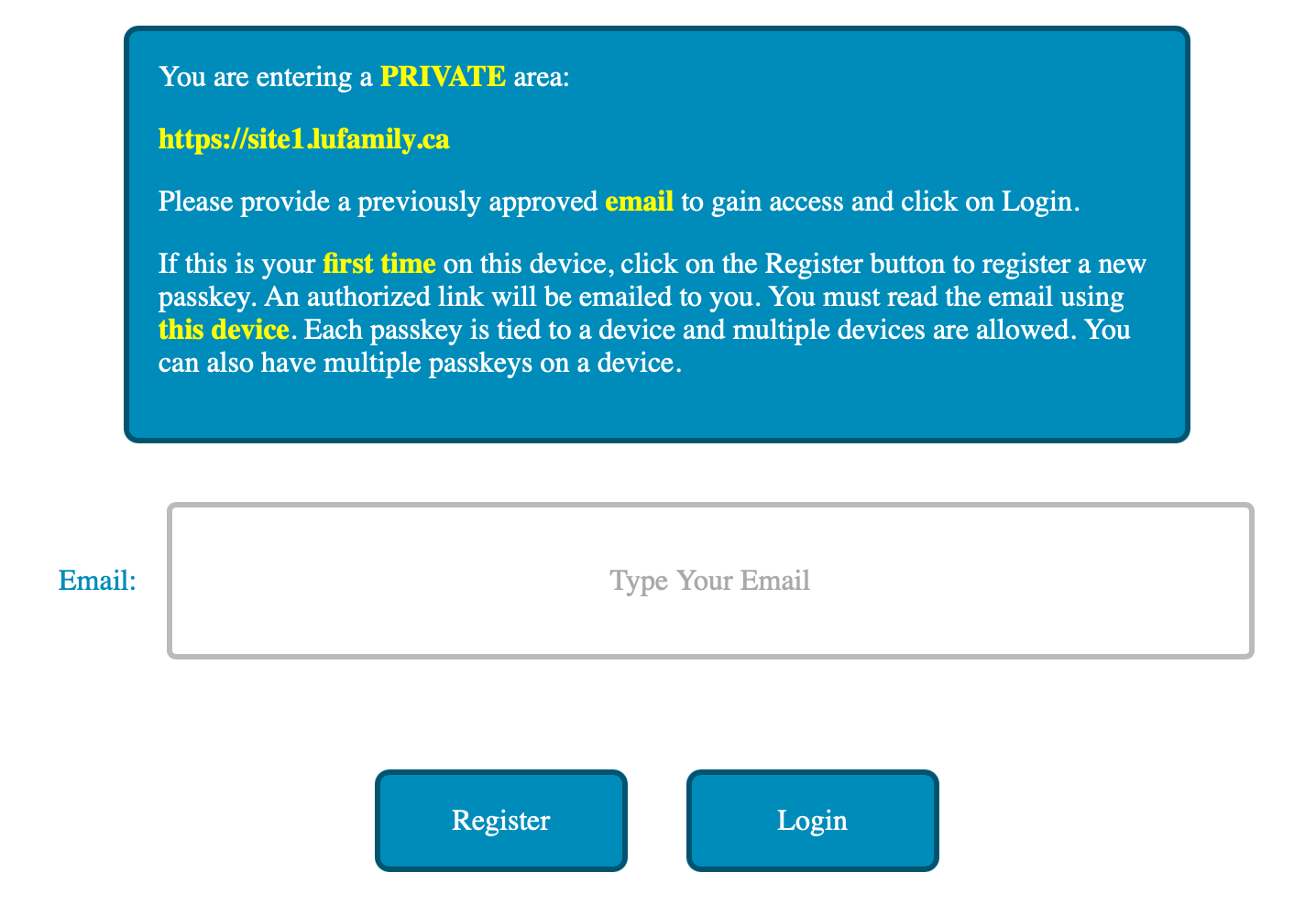
There are no passwords with the above approach. All the users need to remember are the email addresses that they used to register with the site access. The login and registration page looks like this:
Registration and Login Page
For access provisioning, I simply use a JSON file to bind the email address to the allowed web sites. Below is an example:
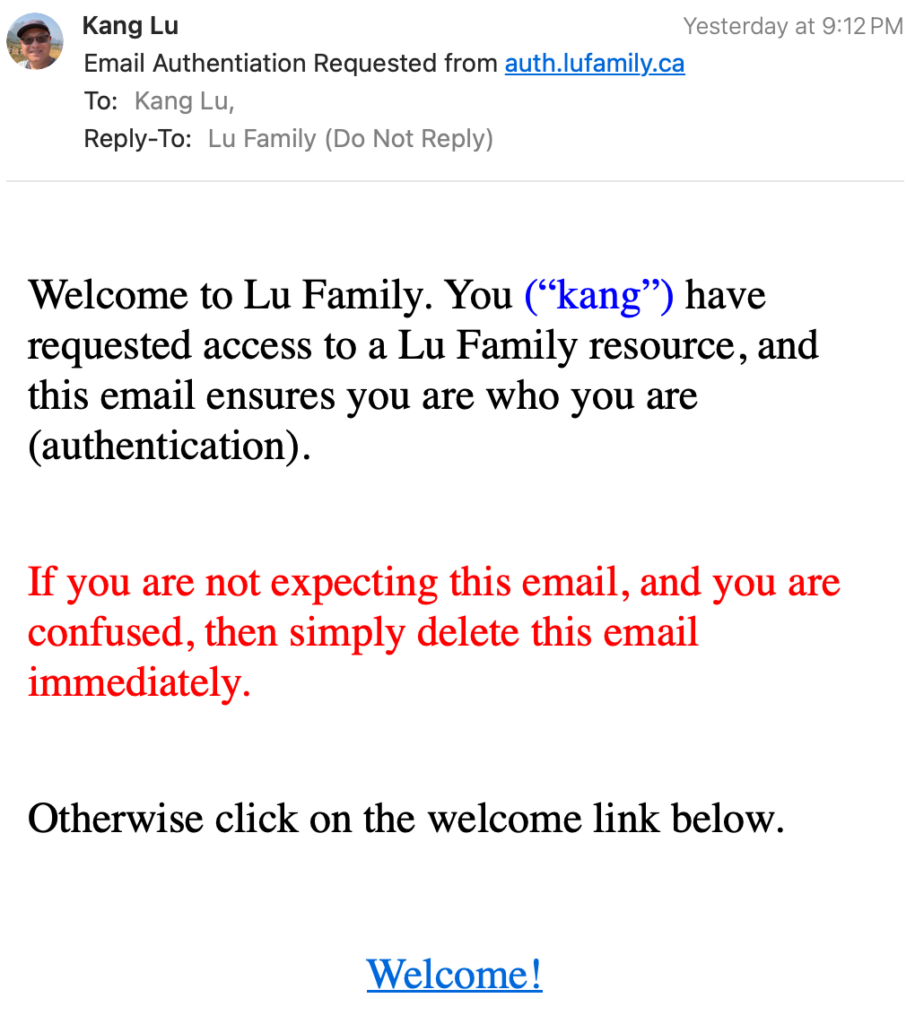
When the user registers, they will receive an email looking like:
Sample onboarding or registration email
In the beginning, I wrote custom code on my web site to use my identity service. However I found out I can write an Apache Lua script to check for token provisioning and invoking of the identity service. I needed some other Lua packages to write my script so I had to figure out which version of Lua is my Apache2 using.
These three packages allow me to process JSON data structures, and communicate with my identity server (auth.lufamily.ca). This way I can add authentication to any sites that I host with Apache2 web server with a virtual host configuration that looks like this:
The checkAuthLuFamily.lua script is used to check if a token is provided either as an HTTP GET parameter, Authorization Bearer value, or a secure, http-only cookie. The token is actually a JWT token containing user specific attributes derived from the JSON file earlier. This token is provisioned when authentication is successful. If the token is missing, then this means the user has yet to be authenticated so we automatically redirect them to the registration page. If the token is valid, then the script will store a new refreshed token with extended expiry (another 30 minutes) into the environment variable which we use to reset the cookie. Any future requests to the same site will preserve the cookie/token.
I love this flexibility. This means I can add authentication to any site that I host with Apache2 without changing the code or modifying the site. This also means that I can develop future sites and services without having to worry about authentication.
I have not provided the source code here, because I am still testing it, but I wanted to document the concept and the approach, so that I can refer to my own creation in the future.
In a previous post, I discussed creating a brand new VDEV with new drives to replace an existing VDEV. However, there is another approach that I chose to use in a very recent event for my NAS (Network Attached Storage) hard drive when it started to encounter write errors and later checksum errors.
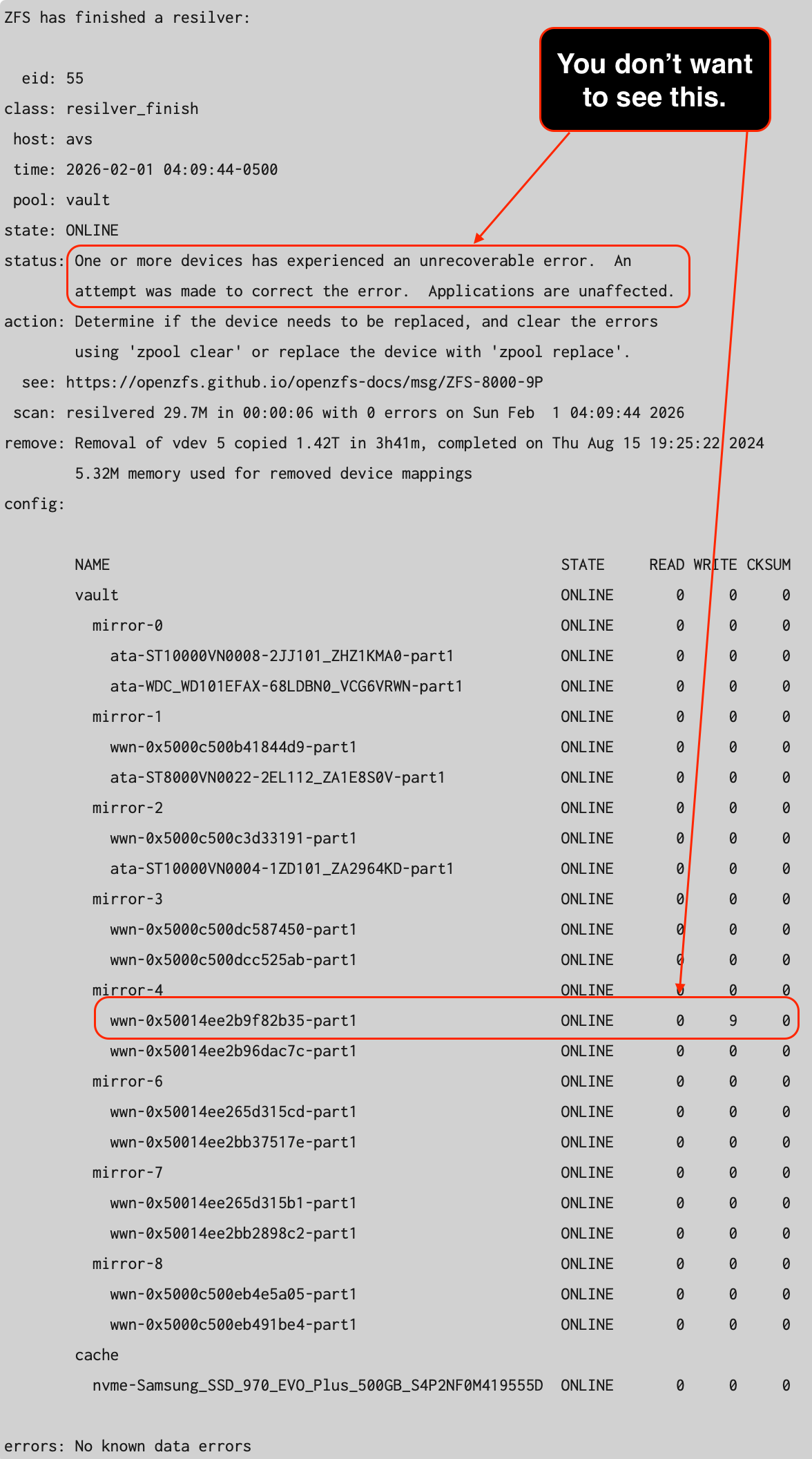
The output of zpool status -v
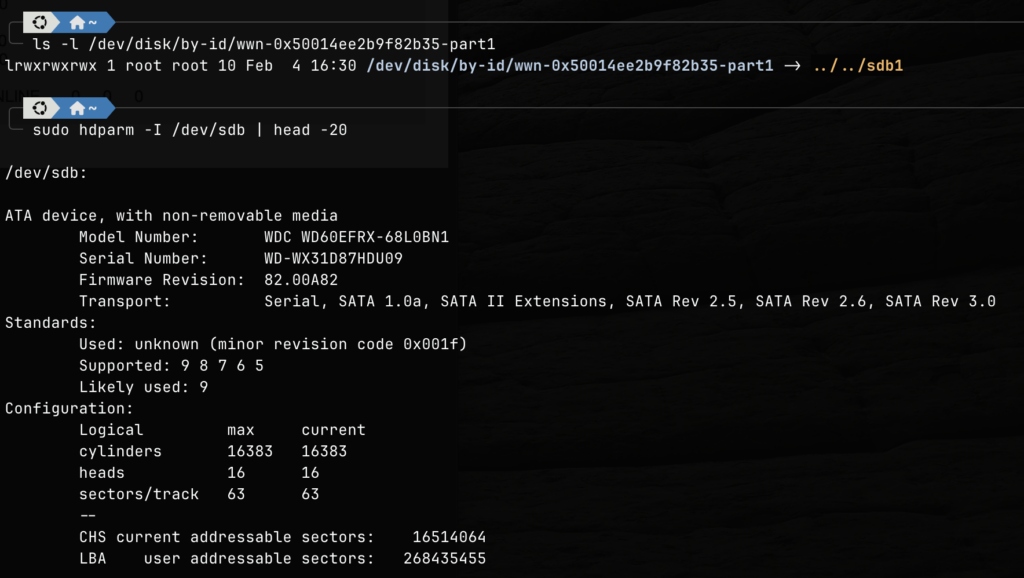
The affected VDEV is mirror-4. Since there are 16 hard drives involved in this storage pool, I had to find out which hard drive is having the issue. I had to perform the following command line operations to obtain the serial numbers of the drives within the VDEV.
Shell commands to get the Serial Number.
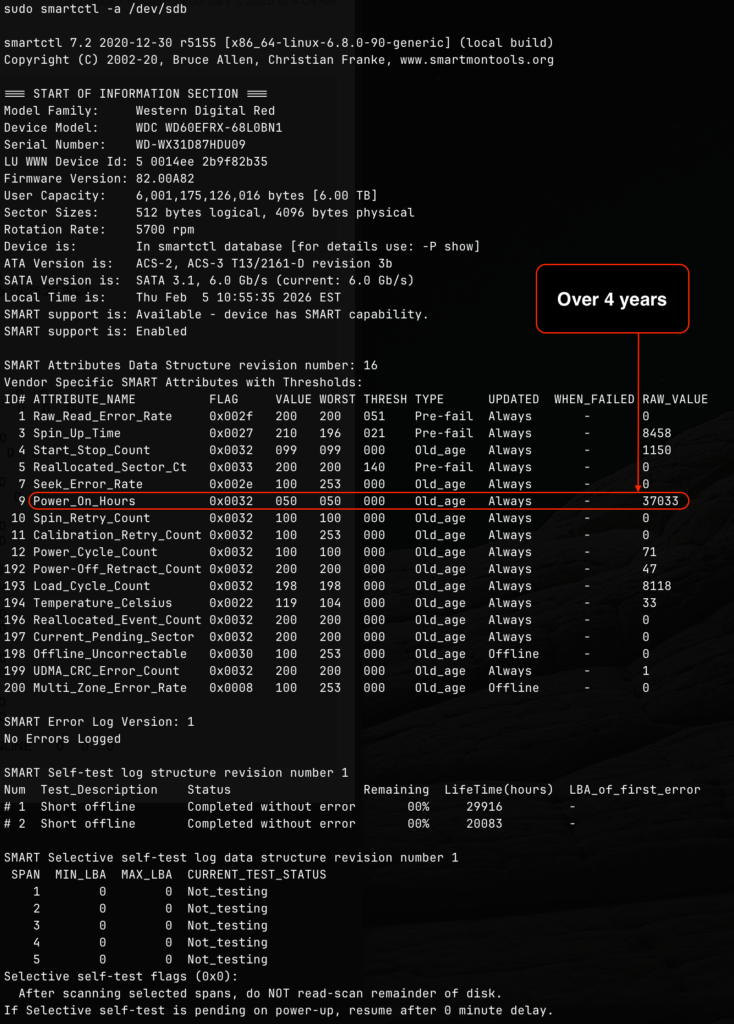
It was the WD60EFRX drive that failed. This is a WD60EFRX Western Digital Red 6TB 5400RPM drive. I was curious to see how old is the drive, so I used the smartctl utility to find out the number of powered on hours that this particular drive endured.
The 4.2 years (37033 / 24 / 365 = 4.2) is well over the 3 years warranty promised by Western Digital, so I took this unfortunate opportunity to get two new Seagate IronWolf Pro 12TB Enterprise NAS Internal HDD Hard Drive. The idea is not just to replace the drive with issue but also to expand the pool, and get an extra 6TB drive from the existing mirror that is still good, and use it as part of my offline backup strategy.
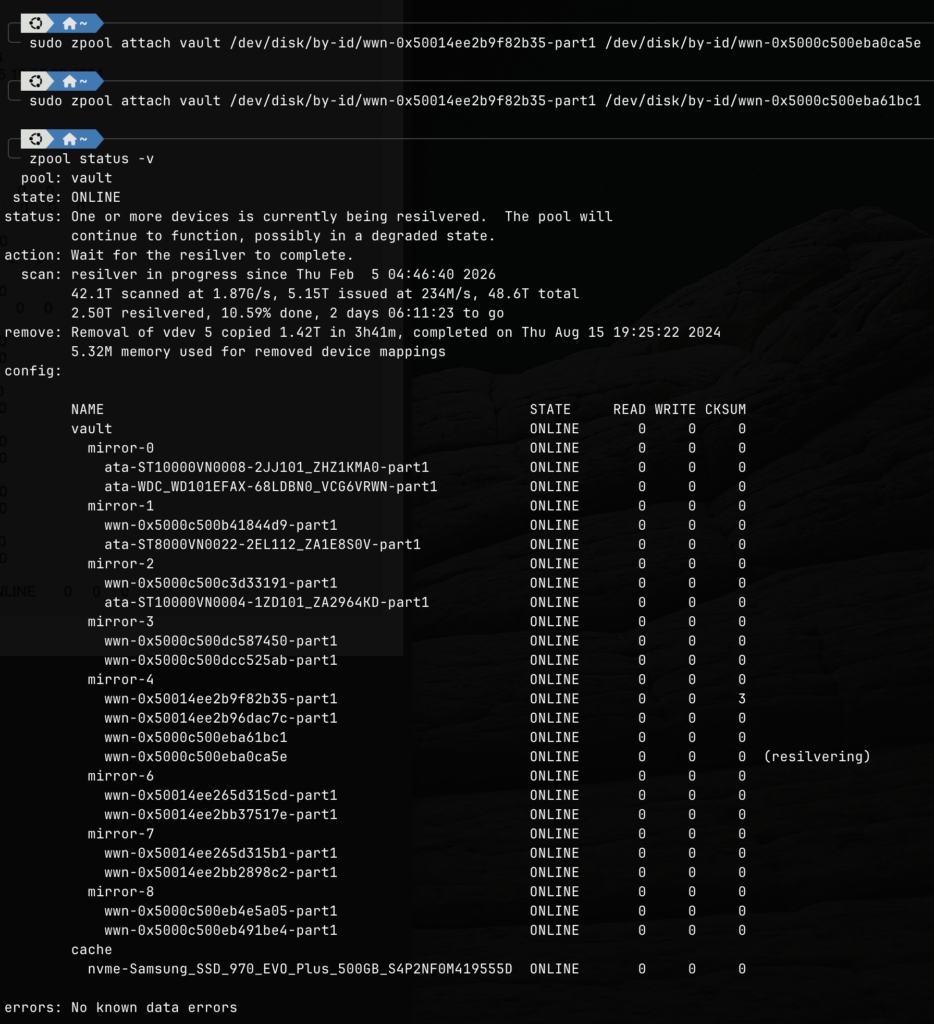
Once the new drives arrived and connected to the system, I simply performed an attach command to add them to the mirror VDEV.
commands to attach the new drive
After attaching the new drives, the zfs pool begins to automatically resilver. The above image was taken several hours after the attachment, and we are now waiting for the last drive to complete its resilvering. Since one of the new drive has already completed its resilvering, this means we have regained full redundancy.
After the resilvering is completed, I will then detach both old drives from the mirror using the detach command.
The first drive will be chucked into the garbage bin, and the second drive will be used for offline backup. Before I use the second drive for offline backup, I need to remove all zfs information and meta data from the drive to avoid any unintentional future conflicts. We do this using the labelclear command like below.
For extra safety, we can also destroy the old partition by using parted and relabeling the disk and create a new partition table. If the above command fails, we can use the dd command to just zero out the first few blocks of the drive.
In summary, this is the general strategy moving forward. When a drive on my NAS pool starts to fail (before actual failure), I take the opportunity to replace all the drives in the entire mirror with higher capacity drives, and use the remaining good one to serve as offline backup.
Since I had difficulties in upgrading my NAS, as I detailed here on this post. I decided that I need to move my NAS services to another server called, workervm. The first service that I decided to move is this web site, my blog, which is a WordPress site hosted by an Apache2 instance with a MySQL database backend.
I decided that instead of installing all the required components on workervm, I will use run WordPress inside a podman container. I already have podman installed and configured for rootless quadlet deployment.
The first step is to backup my entire WordPress document root directory and moved the contents to the target server. I placed the contents on /mnt/hdd/backup on workervm. I also need to perform a dump of the SQL database. On the old blog server, I had to do the following:
I then proceeded to create the following network, volume, and container files on workervm in ${HOME}/.config/containers/systemd:
I wanted a private network for all WordPress related containers to share and also ensure that DNS requests are resolved properly. Contents of wordpress.network:
[Unit]
Description=Network for WordPress and MariaDB
After=podman-user-wait-network-online.service
[Network]
Label=app=wordpress
NetworkName=wordpress
Subnet=10.100.0.0/16
Gateway=10.100.0.1
DNS=192.168.168.198
[Install]
WantedBy=default.target
I also create three podman volumes. The first is where the database contents will be stored. Contents of wordpress-db.volume:
[Unit]
Description=Volume for WordPress Database
[Volume]
Label=app=wordpress
Contents of wordpress.volume:
[Unit]
Description=Volume for WordPress Site itself
[Volume]
Label=app=wordpress
We also needed a volume to store Apache2 related configurations for WordPress. Contents of wordpress-config.volume:
[Unit]
Description=Volume for WordPress configurations
[Volume]
Label=app=wordpress
Now with the network and volumes configured, lets create our database container with wordpress-db.container:
[Unit]
Description=MariaDB for WordPress
[Container]
Image=docker.io/library/mariadb:10
ContainerName=wordpress-db
Network=wordpress.network
Volume=wordpress-db.volume:/var/lib/mysql:U
# Customize configuration via environment
Environment=MARIADB_DATABASE=wordpress
Environment=MARIADB_USER=wordpressuser
Environment=MARIADB_PASSWORD=################
Environment=MARIADB_RANDOM_ROOT_PASSWORD=1
[Install]
WantedBy=default.target
Note that the above container refers database volume that we configured earlier as well as the network. We are also using the community forked version of MySQL (MariaDB).
Finally we come to the configuration of the WordPress container, wordpress.container:
[Unit]
Description=WordPress Application
# Ensures the DB starts first
Requires=wordpress-db.service
After=wordpress-db.service
[Container]
Image=docker.io/library/wordpress:latest
ContainerName=wordpress-app
Network=wordpress.network
PublishPort=8168:80
Volume=wordpress.volume:/var/www/html:z
Volume=wordpress-config.volume:/etc/apache2:Z
# Customize via Environment
Environment=WORDPRESS_DB_HOST=wordpress-db
Environment=WORDPRESS_DB_USER=wordpressuser
Environment=WORDPRESS_DB_PASSWORD=################
Environment=WORDPRESS_DB_NAME=wordpress
[Install]
WantedBy=default.target
Notice the requirement for the database container to be started first, and this container also uses the same network but the two volumes are different.
We have to refresh the system since we changed the container configurations.
systemctl --user daemon-reload
We can then start the WordPress container with:
systemctl --user start wordpress
Once the container is started, we can check both the WordPress and its database container status with:
The copy will take some time, and once it is completed, we have to fix the permissions and ownerships. Note that both of these have to be performed with podman unshare command so that proper uid and gid mapping can be performed.
Lastly I needed to modify my main/old Apache server where the port forwarding is directed to so that blog.lufamily.ca requests are forwarded to this new server and port.
Define BlogHostName blog.lufamily.ca
Define DestBlogHostName workervm.localdomain:8168
<VirtualHost *:443>
ServerName ${BlogHostName}
ServerAdmin kangclu@gmail.com
DocumentRoot /mnt/airvideo/Sites/blogFallback
Include /home/kang/gitwork/apache2config/ssl.lufamily.ca
SSLProxyEngine on
ProxyPreserveHost On
ProxyRequests Off
ProxyPass / http://${DestBlogHostName}/
ProxyPassReverse / http://${DestBlogHostName}/
# Specifically map the vaultAuth.php to avoid reverse proxy
RewriteEngine On
RewriteRule /vaultAuth.php(.*)$ /vaultAuth.php$1 [L]
ErrorLog ${APACHE_LOG_DIR}/blog-error.log
CustomLog ${APACHE_LOG_DIR}/blog-access.log combined
</VirtualHost>
Note that on the old server I still have the document root pointed to a fallback directory. In this fallback directory I have php files that I needed to be served directly without being passed to WordPress but the requested path shares the same domain name as my WordPress site. The rewrite rule performs this short circuit processing. When vaultAuth.php is requested, we skip the reverse proxy all together.
This is working quite well. I am actually using the new location of this blog site to write this post. I plan to migrate the other services on my NAS in a similar manner with podman.
The idea is that once the majority of the services have been ported to workervm, then I can reinstall my NAS with a fresh install of Ubuntu 24.04 LTS without doing a migration.
Update 2026-02-28:
I had to move my blog to a different virtual machine because the current one had a network stack corruption. What I found was that the podman volume concept was super handy. I was able to use podman import/export commands to easily move my blog storage and database without having to worry about permissions and other file system nuances.
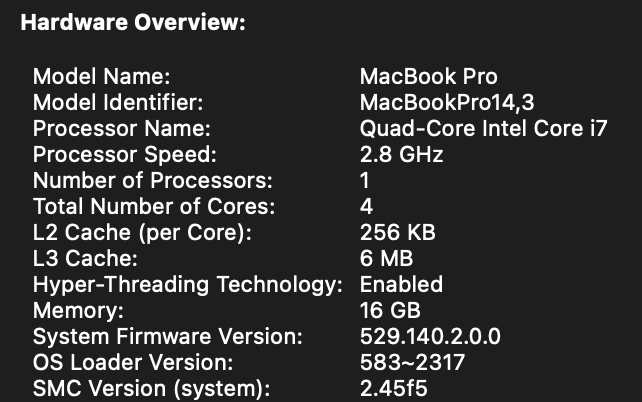
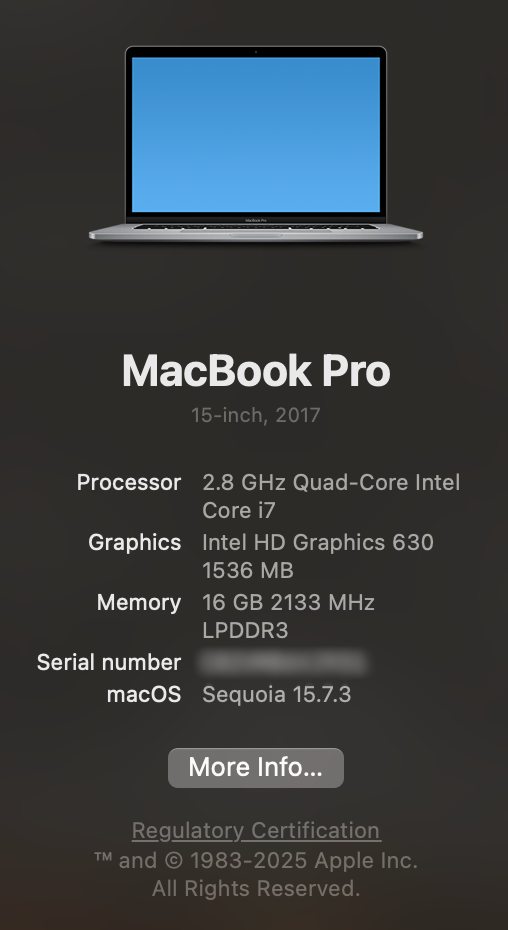
I have a couple of old MacBook Pro’s from late 2016 (MacBook Pro 13,3) and another one from mid 2017 (MacBook Pro 14,3). These laptops have been sitting on my shelves since the pandemic. In 2023 I upgraded them with Sonoma using OpenCore Legacy Patcher (OCLP). I documented the process here. Both of these laptops are Intel based Mac and they have the infamous Touch Bar. These computers are no longer compatible with the most recent macOS. At the time of writing, the latest version is macOS 26 code named Tahoe.
Old laptop hardware spec’s
My original idea in 2026 is to install a suitable Linux distribution. I prepared three distributions:
Linux Mint
Lubuntu
Zorin OS
After several hours of trying these distributions, they all had issues with the Wifi. The driver simply fail to install. A laptop without Wifi is somewhat pointless because you cannot move around with them. Another show stopper with Linux is that we cannot get the Touch Bar to work. At first I didn’t think it was a big deal until I realized that the all important ESC key and all the function keys are on the Touch Bar. Therefore, it is somewhat impractical.
At this point, I was going to chuck them into the e-waste bin, and then I remember that a couple of years ago I played with OCLP. This is a little app that allows you to download a version of macOS installer and create a bootable USB drive with a boot-loader that will make certain firmware adjustments so that an incompatible macOS can be installed on old unsupported hardware, such as these laptops. This time instead of Sonoma, we’ll install Sequoia.
Unfortunately, OCLP still does not support macOS Tahoe, but Sequoia is not too bad. On another Intel based Mac mini, I prepared a bootable USB drive with Sequoia using OCLP, and then I went into the program’s settings to select my targeted Mac model. This allows the program to build and install OpenCore on to the same USB boot drive’s EFI partition.
Once the USB drive is prepared with BOTH the installer and the OpenCore EFI partition with the selected targeted hardware (in our case either MacBook Pro 13,3 or 14,3), we can then use the bootable USB drive on our old MacBooks.
Sequoia on a 2017 MacBook Pro!
The installation process begins with powering on the old MacBook with the USB drive plugged in while holding down the Option key. This will show the current bootable OS that we will be replacing, the EFI partition containing OpenCore, and the new installer that we prepared with macOS Sequoia. We want to select the EFI OpenCore first, and then select the Sequoia Installer. This way the installer will be running with the firmware fixes.
When the installer is running, there will be several reboots. Once the install is completed, there is one last step that we must do. We have to perform a Post Install Root Patch. This effectively replace the OS drivers with old drivers that are compatible with your old hardware.
With the OCLP, I was able to get both laptops to run Sequoia giving an 8 and 9 years old laptop new life. However there are downsides:
We cannot perform automated updates from Apple, so I turned off automatic updates and downloads of new OS updates;
When OCLP has a new app version, we will need to create a new OpenCore partition installed on the laptop bootable drive’s EFI partition, and we will also have to reapply the root patches;
We can only update new OS when they are supported by OCLP, so for Tahoe we will have to await a new version;
I think the disadvantages are negligible when compared to just throwing away the hardware.
I still have a 10+ years old MacBook Air which I look forward to trying with Sequoia.
Last Saturday, I decided it was time to switch my NAS server from 22.04 LTS to 24.04 LTS. I’ve been putting it off for ages, worried that the upgrade might not go as planned and something could go wrong. Since 24.04 is already in its fourth point release, I figured the risks should be manageable and it’s time to take the plunge.
I backup my system nightly so the insurance was in place. After performing a final regular update to the system, I started with the following:
After answering a few questions to save my custom configuration files for different services, it said the upgrade was done. I then rebooted the system, but BOOM! It won’t boot.
The BIOS knows the bootable drive, but when I tried to boot it, it just went back into the BIOS. It didn’t even give me a GRUB prompt or menu.
I figured this wasn’t a big deal, so I booted up the system with the 24.04 LTS Live USB. The plan is to just reinstall GRUB, and hopefully, that will fix the system.
Once I’ve booted into the Live USB and picked English as my language, I can jump into a command shell by pressing ALT-F2. Alternatively, you can press F1 and choose the shell option from the help menu. But, I found that the first method opens up a shell with command line completion, so I went with that.
The boot disk had the following layout (output from both fdisk and parted):
sudo fdisk -l /dev/nvme1n1
Disk /dev/nvme1n1: 931.51 GiB, 1000204886016 bytes, 1953525168 sectors
Disk model: Samsung SSD 980 PRO 1TB
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
Disk identifier: 90B9F208-2D05-484D-8C8C-B3AE71475167
Device Start End Sectors Size Type
/dev/nvme1n1p1 2048 2203647 2201600 1G EFI System
/dev/nvme1n1p2 2203648 1921875000 1919671353 915.4G Linux filesystem
/dev/nvme1n1p3 1921875968 1953523711 31647744 15.1G Linux swap
sudo parted /dev/nvme1n1
GNU Parted 3.4
Using /dev/nvme1n1
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted) p
Model: Samsung SSD 980 PRO 1TB (nvme)
Disk /dev/nvme1n1: 1000GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
1 1049kB 1128MB 1127MB fat32 boot, esp
2 1128MB 984GB 983GB ext4
3 984GB 1000GB 16.2GB linux-swap(v1) swap swap
As I described in this post, we want to make sure that the first partition is marked for EFI boot. This can be done in parted with:
set 1 boot on
set 1 esp on
I didn’t have to perform the above since the first partition (/dev/nvme1n1p1) is already recognized as EFI System. We also need to ensure that this partition is formatted with FAT32. This can be done with:
sudo mkfs.vfat -F 32 /dev/nvme1n1p1
Since this was already the case, I also did not have to perform this formatting step.
The next step is to mount the root directory and the boot partition.
mount /dev/nvme1n1p2 /mnt
mount /dev/nvme1n1p1 /mnt/boot/efi
We now need to bind certain directories under /mnt in preparation for us to change our root directory to /mnt.
for i in /dev /dev/pts /proc /run; do sudo mount --bind $i /mnt$i; done
mount --rbind /dev /mnt/dev
mount --rbind /sys /mnt/sys
mount --rbind /run /mnt/run
mount -t proc /proc /mnt/proc
chroot /mnt
grub-install --efi-directory=/boot/efi /dev/nvme1n1
update-grub
mount --make-rslave /mnt/dev
umount -R /mnt
exit
If we do not use the –rbind option for /sys, then we may get an EFI error when running grub-install. There are two alternatives that solves the same issue, although used less often, you can also choose one of the following (but not BOTH):
mount --bind /sys/firmware/efi/efivars /mnt/sys/firmware/efi/efivars
mount -t efivarfs none /sys/firmware/efi/efivars
The reinstallation of GRUB did not solve the problem. I had to perform a full system restore using my backup. The backup was created using rsync as described on this post. However, I learned that this backup was done incorrectly! I excluded certain directories using the name instead of /name. This caused more exclusion than intended. The correct method of the backup should be:
After the restore, double check that /var/run is soft-linked to /run.
Once the restoration is completed, I follow the above instructions again to re-install GRUB, and I was able to boot back into my boot disk.
Since this upgrade attempt has failed, I now have to figure out a way to move my system forward. I think what I will do is to port all of my services on my NAS as podman root-less quadlets, and then just move the services into a brand new Ubuntu clean installation. This is probably easier to manage in the future.
In a previous post, I commented on our AI server containing an old P40 GPU failed. We replaced our server with the following parts.
Component
Description
CPU
AMD Ryzen 9 9900X 4.4 GHz 12-Core Processor
CPU Cooler
Thermalright Peerless Assassin 120 SE 66.17 CFM CPU Cooler
Motherboard
Asus B650E MAX GAMING WIFI ATX AM5 Motherboard
Memory
Crucial Pro 64 GB (2 x 32 GB) DDR5-6000 CL40 Memory
Storage
Samsung 990 Pro 2 TB M.2-2280 PCle 4.0 X4 NVME Solid State Drive
GPU
2 x EVGA FTW3 ULTRA GAMING GeForce RTX 3090 24 GB Video Card (refurbished)
Case
Fractal Design Meshify 3 XL ATX Full Tower Case
Power Supply
SeaSonic PRIME TX-1600 ATX 3.1 1600 W 80+ Titanium Certified Fully Modular ATX Power Supply
I purchased all of our components at Amazon and the total (including shipping and taxes) came to to be $6,271.22. The most expensive parts were the GPU ($2,979.98), the power supply ($903.95), and then the memory ($843.19). All prices are quoted in Canadian dollars.
I had no issues in building the computer.
As you can see above, after the CPU cooler and the GPU’s were installed you can barely see the motherboard. Although there are still PCIe slots available, there is no more room to actually place new PCIe cards. We still have two more DIMM slots, so we can consider a future memory upgrade.
One of the main concerns I had was to plug this computer into an electrical socket that will not trip any of my breakers. The 1,600W power supply is awfully close to the maximum theoretical limit of a 15A breaker in our house, which would be around 1,800W. This server is too powerful for any of my current UPS units or power bars. It will have to be connected directly to a wall on a circuit that is not loaded by other appliances.
After testing the memory using MemTest, I installed Ubuntu Server 24.04.3 LTS. To prepare the machine for AI work load, I will then need to install Nvidia CUDA.
Installing CUDA
The first step that I did was to install the Nvidia CUDA. I followed the steps here for Ubuntu. I specifically follow the Network Repository Installation directions.
It took a minute or two to download the model and initialize the GPU’s. Once it is up and running, I verified that it was running by using a simple curl command.
❯ curl http://localhost:8000/v1/models | jq .
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 463 100 463 0 0 615k 0 --:--:-- --:--:-- --:--:-- 452k
{
"object": "list",
"data": [
{
"id": "Qwen/Qwen3-14B",
"object": "model",
"created": 1766511858,
"owned_by": "vllm",
"root": "Qwen/Qwen3-14B",
"parent": null,
"max_model_len": 40960,
"permission": [
{
"id": "modelperm-bc2e247073d50d67",
"object": "model_permission",
"created": 1766511858,
"allow_create_engine": false,
"allow_sampling": true,
"allow_logprobs": true,
"allow_search_indices": false,
"allow_view": true,
"allow_fine_tuning": false,
"organization": "*",
"group": null,
"is_blocking": false
}
]
}
]
}
To deploy a model, I created the following systemd unit file in /etc/systemd/system called vllm.service. This way vLLM will automatically start when the host is rebooted.
[Unit]
Description=vLLM OpenAI Compatible Server
After=network.target
[Service]
# User and Group to run the service as (e.g., 'youruser', 'yourgroup')
User=kang
Group=kang
# Set the working directory
WorkingDirectory=/home/kang/py_vllm
Environment=VLLM_USE_V1=1
# The command to start the vLLM server
# Use 'exec' to ensure systemd correctly manages the process
ExecStart=/home/kang/py_vllm/vllm_cuda13_env/bin/python -m vllm.entrypoints.openai.api_server --model Qwen/Qwen3-14B --host 0.0.0.0 --port 8000 --tensor-parallel-size 2 --enable-auto-tool-choice --tool-call-parser hermes
# Restart the service if it fails
Restart=always
[Install]
WantedBy=multi-user.target
I used 0.0.0.0 as the host so that any machine on the network can connect to the service. If you use 127.0.0.1, only local sessions can connect.
To enable the above service, I had to do the following:
I also enabled tooling for my Opencode.ai experiments. vLLM ended up using all of 48GB VRAM on both GPU’s for the Qwen LLM as well as for caching. Impressive!
Installing Podman and Prepare for Quadlets
For everyday chats, I also configured a version of Perplexica. I chose to use Podman to install this, specifically using Podman Quadlet. The idea is to run Perplexica under my user id (kang), instead of running it as root. Our first step is to install Podman and prepare our user account for quadlets.
Note aside from explicit sudo references all other commands are run as the user.
Install Podman:
sudo apt install podman
The container requires user and group ids so we need to map id spaces to my user account.
We need to have an active user session for the container after a reboot, so we need my account to linger around.
sudo loginctl enable-linger ${USER}
We need to proactively increase the kernel key size to avoid any exceeding quota situations like, “Disk quota exceeded: OCI runtime error”. Not just for this container, but also for any other future containers.
echo "kernel.keys.maxkeys=1000" | sudo tee -a /etc/sysctl.d/custom.conf
Lastly, we need to prepare two directories for the containers. The first will house the systemd unit definition of the container. The second is a directory that will act as local storage for the container.
If we have any previous containers running, we need to perform a system migrate. I did not perform this, because I ensure that I had no other Podman containers running. You also can enable the auto update feature for podman. I also did not do this, as I prefer to this manually.
podman system migrate
systemctl --user enable --now podman-auto-update
For a more control networking experience and behaviour, we want to create our own container network. This will also help with DNS resolution. We need to create the network definition in $HOME/.config/containers/systemd/${USER}.network be sure to replace ${USER} reference below with the actual user account name.
Note that the above commands are run with the user account and not with sudo or as root. Also note the --user option.
Once the service is running, you can get its logs by doing the following:
journalctl --user -u perplexica
You can also see all containers running as quadlets using:
systemctl --user status
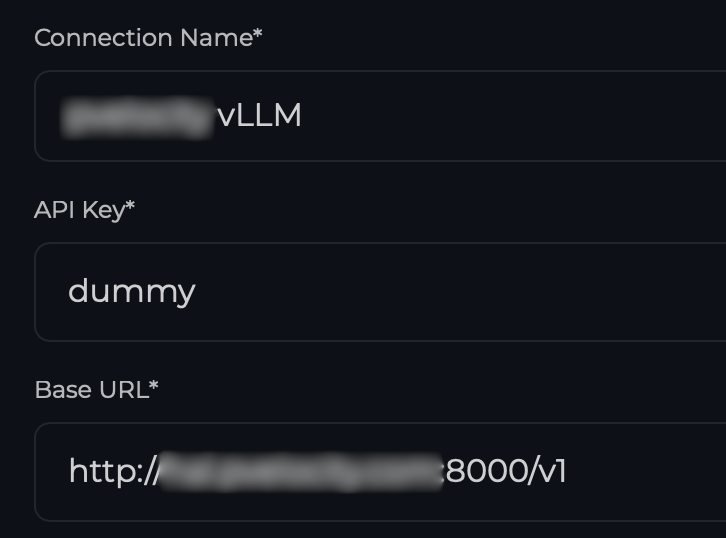
With Perplexica running, we can proceed to its Web UI (http://localhost:3000) using our browser and point to our vLLM instance by creating an OpenAI connection type.
Once the connection is established, you can proceed to add the Chat and Embedding Models. In our case I used Qwen/Qwen3-14B as the model key. This is the same as the model id that vLLM is currently serving. The model name can be anything you assign.
That is it! We now have a local chat service with Perplexica, and I can use the OpenAI compatible API with vLLM.
Here is an example of using CURL with the API:
❯ curl -X POST "http://localhost:8000/v1/responses" \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen3-14B",
"input": "How are you today?"
}' | jq -r '.output[0].content[0].text'
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1791 100 1721 100 70 448 18 0:00:03 0:00:03 --:--:-- 466
<think>
Okay, the user asked, "How are you today?" I need to respond appropriately. First, I should acknowledge their greeting and express that I'm doing well. Since I don't have feelings, I can't experience emotions, but I can simulate a friendly response. I should keep it positive and open-ended to encourage further conversation. Maybe add an emoji to keep it friendly. Also, I should invite them to ask questions or share something. Let me check if the response is natural and not too robotic. Avoid any technical jargon. Make sure it's concise but warm. Alright, that should work.
</think>
I'm doing great, thank you! I'm always ready to chat and help out. How about you? 😊 What's on your mind today?
We have several UPS (Uninterruptible Power Supply) units around the house. They are there to prevent power interruptions to networking equipment and computer servers. When you are into home automation, keeping these services up and running is almost essential.
Previously this year, I noticed one of the UPS unit keeps on chirping and the body of the UPS unit was warm to the touch. I noticed on the LED display, that its battery is due to be replaced. This was not an issue. However I treated this as a cautionary tale because some of my UPS units were situated within the house that I rarely visit, so I may not hear the beeping alerts and may end up being a potential fire hazard should the battery misbehave. I decided that I needed to monitor my UPS units more frequently.
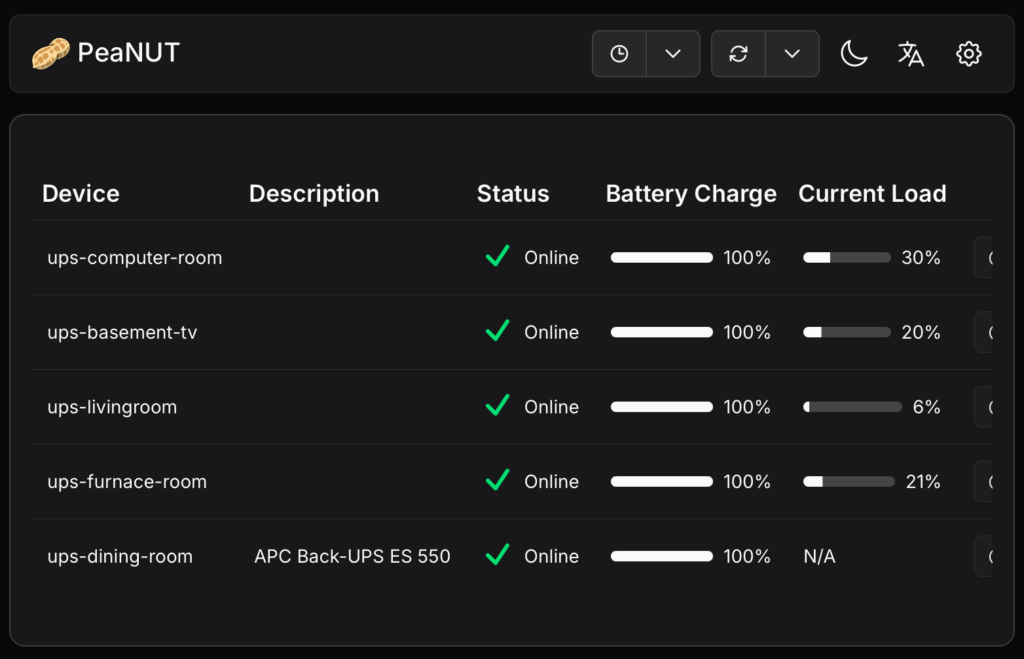
I started to learn about NUT (Network UPS Tools), and went on a mission to deploy this solution so that I can centrally monitored all of my UPS on a single web site. The first step is to ensure that all of my UPS can physically communicate its status to a computer host. This means they all have to be connected with a USB port.
Once communication is established, I then had to install NUT software on each of the computer hosts. My UPS units were installed on different hosts consisting of Raspberry PI, Ubuntu Linux, and Mac, so I had to configure each properly. Below is a summary of the configuration steps.
# lsusb
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 001 Device 002: ID 0764:0601 Cyber Power System, Inc. PR1500LCDRT2U UPS
Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub
Inside ups.conf: Copy the above output from nut-scanner into end of the file and be sure to change the ups-nameinto something that is unique.
Inside upsmon.conf: Remember to replace ups-name.
MONITOR ups-name 1 upsmon secret primary
Inside upsd.conf:
LISTEN 0.0.0.0 3493
LISTEN ::1 3493
Inside upsd.users:
[upsmon]
password = secret
actions = SET
instcmds = ALL
upsmon primary
Finally we need add a file in /etc/udev/rules.d which governs whether we can send commands to the UPS. We need to create a file called 99-nut-ups.rules and that file should contain the following content:
You can also perform actions on the UPS unit. First we can query a list of commands that we can execute on the UPS. Note that with this example the UPS is being queried by a remote host hence the usage of avs.localdomain instead of localhost.
# upscmd -l ups-computer-room@avs.localdomain
Instant commands supported on UPS [ups-computer-room]:
beeper.disable - Disable the UPS beeper
beeper.enable - Enable the UPS beeper
beeper.mute - Temporarily mute the UPS beeper
beeper.off - Obsolete (use beeper.disable or beeper.mute)
beeper.on - Obsolete (use beeper.enable)
load.off - Turn off the load immediately
load.off.delay - Turn off the load with a delay (seconds)
shutdown.reboot - Shut down the load briefly while rebooting the UPS
shutdown.stop - Stop a shutdown in progress
test.battery.start.deep - Start a deep battery test
test.battery.start.quick - Start a quick battery test
test.battery.stop - Stop the battery test
test.panel.start - Start testing the UPS panel
test.panel.stop - Stop a UPS panel test
Reading the above, we see that we can perform a quick battery test by sending the command test.battery.start.quick. We do this with:
The configuration files are stored in /usr/local/etc/nut.
Since there is no lsusb or nut-scanner on the Mac, you can use the following command to see if the UPS is connected with USB or not.
system_profiler SPUSBHostDataType
You can also use:
pmset -g ps
The ups.conf file is more simple, because you don’t need the other details:
[ups-dining-room]
driver = macosx-ups
port = auto
desc = "APC Back-UPS ES 550"
All other configuration files is the same and there is no need to create the /etc/udev/rules.d file.
I need to start nut when the Mac reboots, so I need to configure launchd for this. First I created two scripts, start.sh and stop.sh in the ~/Applications/nut. Below are their respective contents:
sudo launchctl bootstrap system /Library/LaunchDaemons/home.nut.custom.plist
Now the NUT daemon will be running when we reboot the Mac.
PEANUT Installation
Once this is all done, I am then able to retrieve all of my UPS units’ status from anywhere on my network as long as I have the nut-client package installed and have access to the upsc command. We are now ready to install the PEANUT web interface using podman.
On a computer host that is running other centralized services within my house, We performed the following steps.
We created the following systemd unit file called: /etc/systemd/system/peanut.service, which contains the following:
The above file was generated with the podman utility itself using:
podman generate systemd --new --files peanut
For the above to work, there must be a container peanut running first, which we did with the following command just to temporary create the file. This also assumes a local config directory is created for the volume mapping.
I have an old Raspberry Pi running Volumio to stream my music library to my living room home theatre. This morning, I needed to perform an update from Volumio 3 to Volumio 4. After I did the upgrade, the Raspberry Pi acquired a new IP address, which I need to discover through my Unifi Dream Machine Pro (UDMPro) Max web based user interface. It is then that I noticed that all the virtual machines hosted using Proxmox running on our AI Server have dropped off from my network. This is the AI Server that I built back in August of 2023, and discussed in this post.
I thought all I needed to do was a reboot, still no network connection. The networking interface seems to be off. I plug in a keyboard into the server, and added a monitor. No video signal, and the keyboard did not respond, not even the NUMLOCK LED worked. This is not good. All signs point to a hardware failure.
I pulled out PCIe cards one by one and try to resuscitate the server. No good. With a bare-bones motherboard, memory, and CPU, it still did not respond. I couldn’t even get into the BIOS. The fans were spinning, and the motherboard diagnostic LED’s point to some error when it is trying to initiate video / VGA.
I ended up finding a possible replacement motherboard, Gigabyte B550 Gaming X V2, at a local Canada Computers for $129 (before tax), and some thermal paste for $9.99 (before tax) to reseat the CPU and the cooler.
Replacement Board
The good news is that after replacing the motherboard, I was able to get into the BIOS. However when I try to boot the machine with the used Nvidia P40 card, it failed to boot again. I had to forego this card. The GPU could have been damaged by the old mainboard, or the GPU could have been damaged first and caused the mainboard to fail. At this point I am too tired to play the chicken or the egg game. I simply left the card out, and restore Proxmox on the server. It will no longer be an AI server, but at least the virtual machines on the server can be recovered.
Proxmox boots but will not shutdown. I had to undo the PCIe passthrough configurations that I did when I build the AI Server. This involved editing the GRUB configuration so that all the special options are removed in /etc/default/grub:
GRUB_CMDLINE_LINUX_DEFAULT=""
Before it had configurations containing options to make use of IOMMU and the vfio modules. After this update, I had to perform the following commands:
update-grub
update-initramfs -u -k all
I then proceed to reboot the system, and the system behaved normally. During this process I also found out that Proxmox will not start normally if any of the mounts configured in /etc/fstab are not available. This threw me for a loop because the regular USB backup drive was disconnected when I was trying to resolve this issue.
Since the PCIe bus has different peripherals, I knew from my past experience which I detailed here, I have to edit the /etc/network/interfaces file with the new interface name. The following command really helped me identify the new name and which NIC I should pick, because there were multiple interfaces, and I wanted to pick the 2.Gbps one.
lshw -class network
In the end, all of the virtual hosts are now up and running. I hope this new motherboard proves to be more stable without the used P40 GPU. Fingers crossed!